|
I’m now a Principal Researcher at Tencent Singapore. Before that, I was a Research Scientist at ByteDance. I received my Ph.D. degree and B.E. degree from Huazhong University of Science and Technology (HUST) in 2020 and 2015 respectively, advised by Prof. Wenyu Liu and Prof. Xinggang Wang. I was working as a visiting student (2018-2019) in the IFP group at the University of Illinois at Urbana-Champaign (UIUC), advised by Prof. Thomas S. Huang, Prof. Yunchao Wei and Prof. Humphrey Shi. I am currently working on Multimodal Interaction, specializing in multimodal agents, multimodal pretraining, and efficient model architecture. CV / Email / GitHub / Google Scholar / LinkedIn [Hiring!] Our team is actively recruiting scientists, engineers and interns in China and Singapore, with a particular focus on Computer-Use Agent/MLLM. Feel free to contact me if you are interested. |

|
|
|
My selected publications are listed here. The complete list of publications can be seen from my Google Scholar page. ^ Intern. * equal contribution. † corresponding author |
|
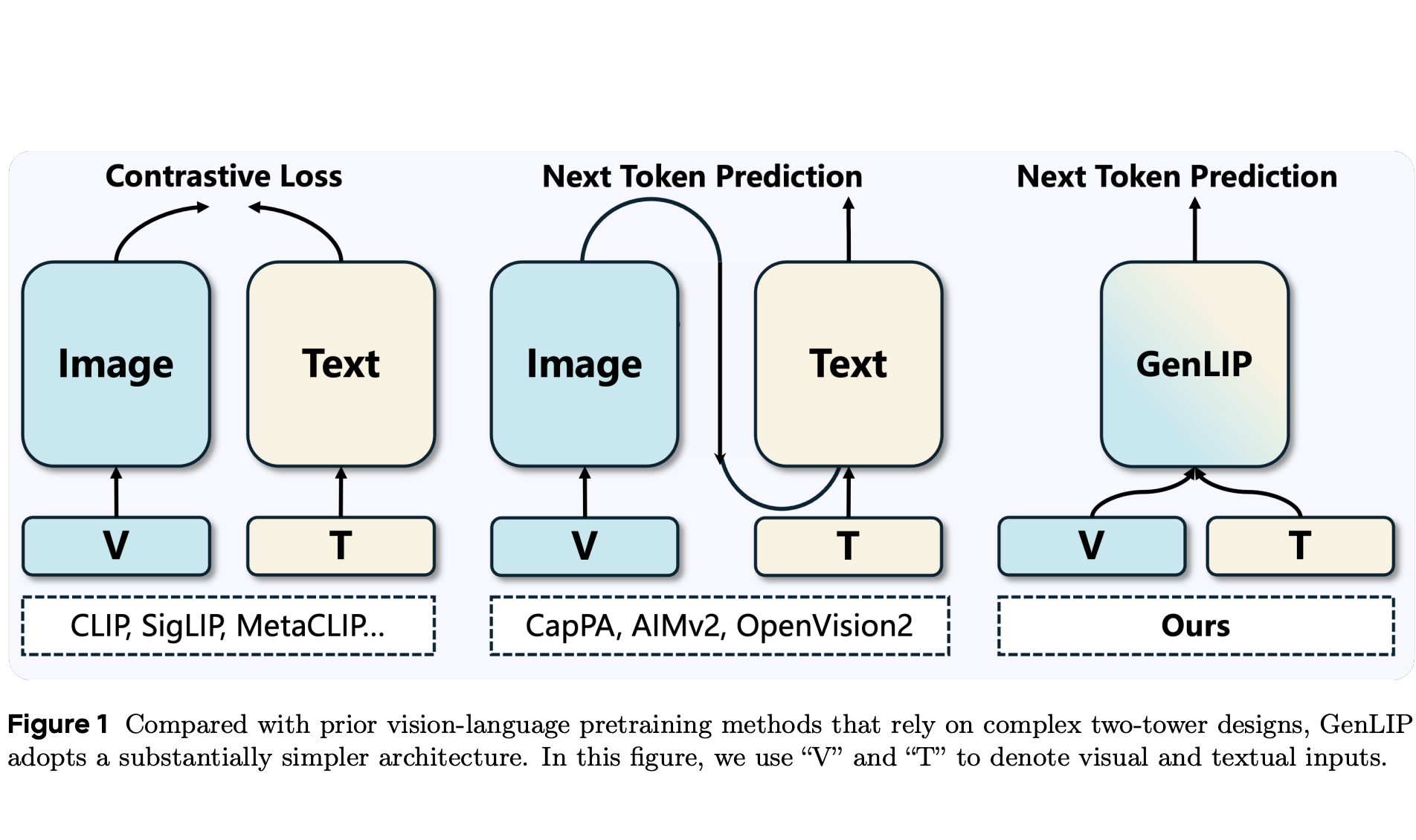
Yan Fang^*, Mengcheng Lan^*, Zilong Huang†, Weixian Lei, Yunqing Zhao, Yujie Zhong, Yingchen Yu, Qi She, Yao Zhao, Yunchao Wei†. ECCV 2026 code / pdf To better align vision encoders with the autoregressive nature of LLMs, GenLIP trains a ViT to predict language tokens directly from visual tokens using a standard language modeling objective, without contrastive batch construction or an additional text decoder. |
|
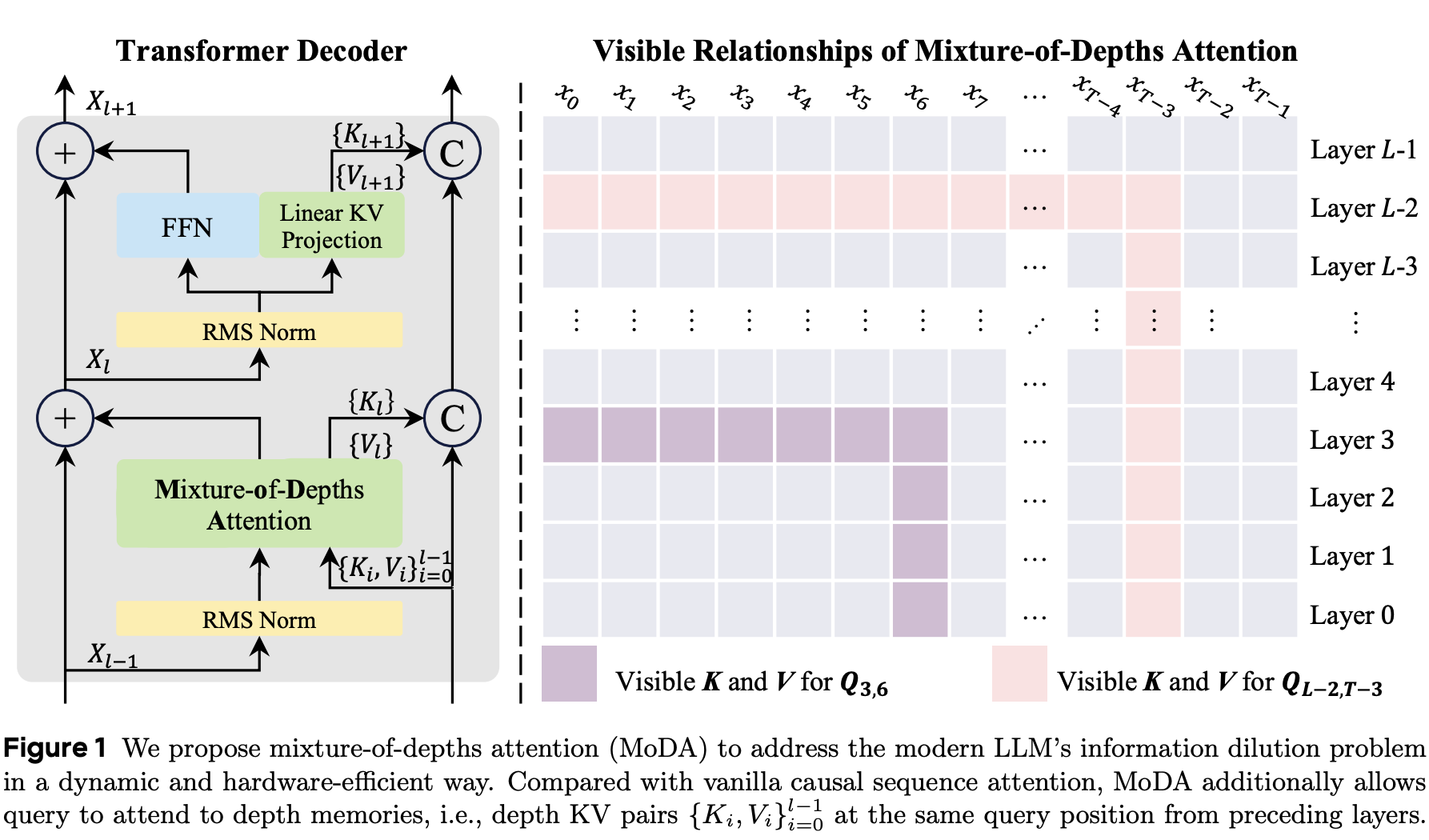
Lianghui Zhu, Yuxin Fang, Bencheng Liao, Shijie Wang, Tianheng Cheng, Zilong Huang, Chen Chen, Lai Wei, Yutao Zeng, Ya Wang, Yi Lin, Yu Li, Xinggang Wang Arxiv 2026 code / pdf We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. |
|
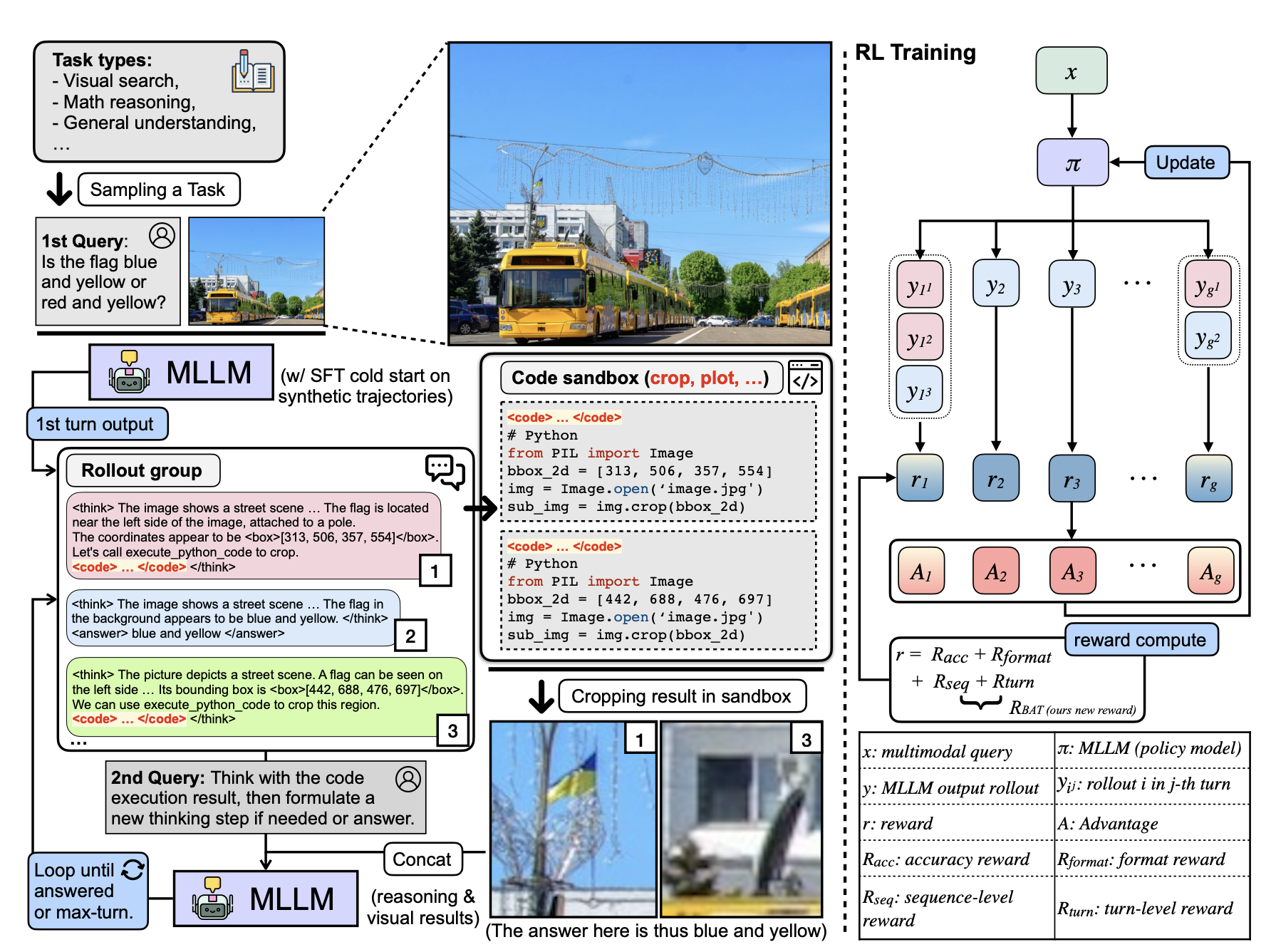
Qi Song^*, Honglin Li^*, Yingchen Yu, Haoyi Zhou, Lin Yang, Song Bai, Qi She, Zilong Huang†, Yunqing Zhao† CVPR 2026 code&data / pdf We introduce CodeDance, which explores executable code as a general solver for visual reasoning. |

|
Weiheng Zhao, Zilong Huang†, Jiashi Feng, Xinggang Wang. NeurIPS 2025 code / pdf We propose SuperCLIP, a simple yet effective framework that augments contrastive learning with classification-based supervision. With just a 0.077% increase in total FLOPs and no need for additional annotated data, it can significantly improve the performance of visual models. |
|
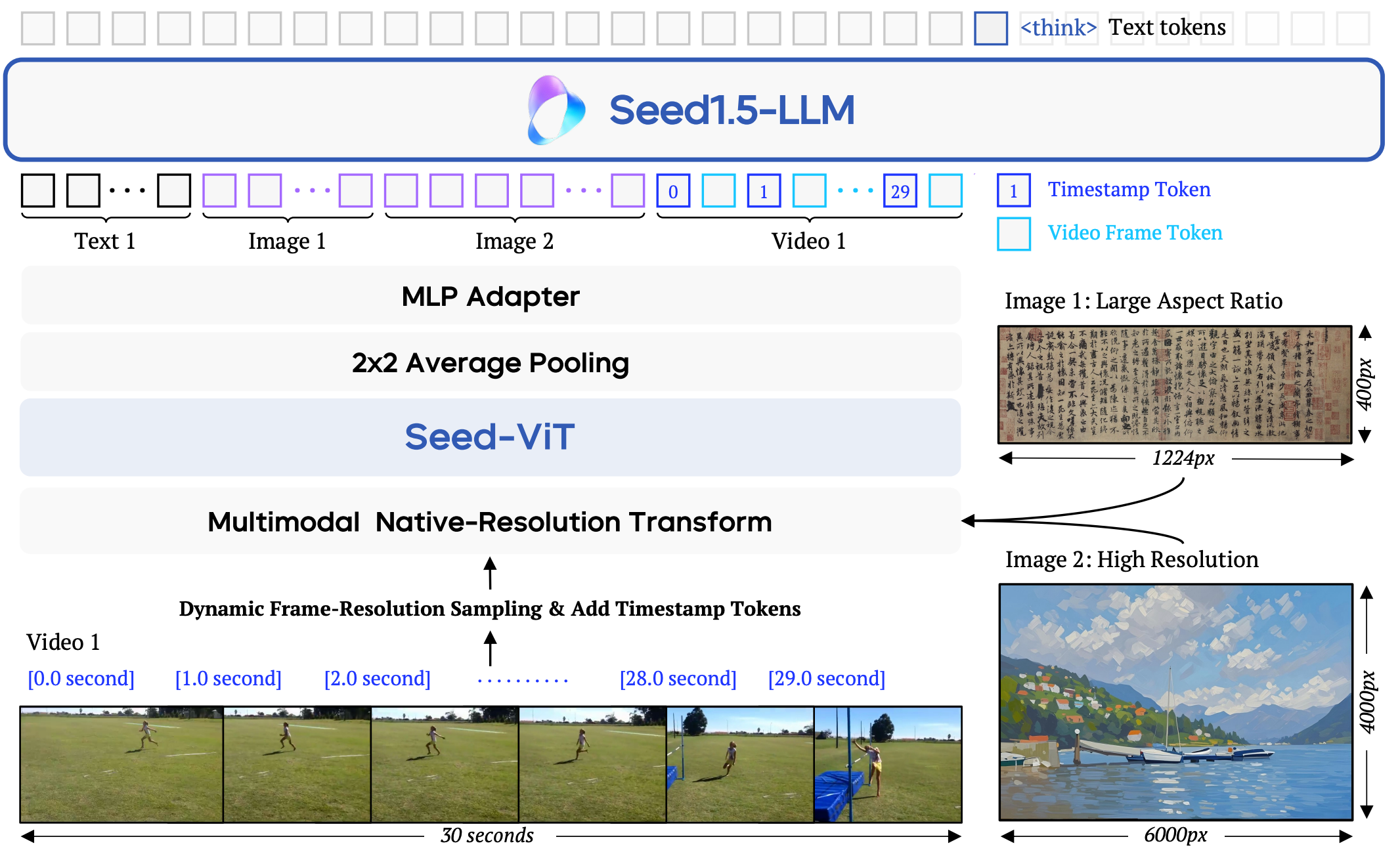
ByteDance Seed. Arxiv 2025 website / pdf My primary responsibility was to conduct research on vision-language pre-training and to build the training pipeline of Seed-ViT. |
|
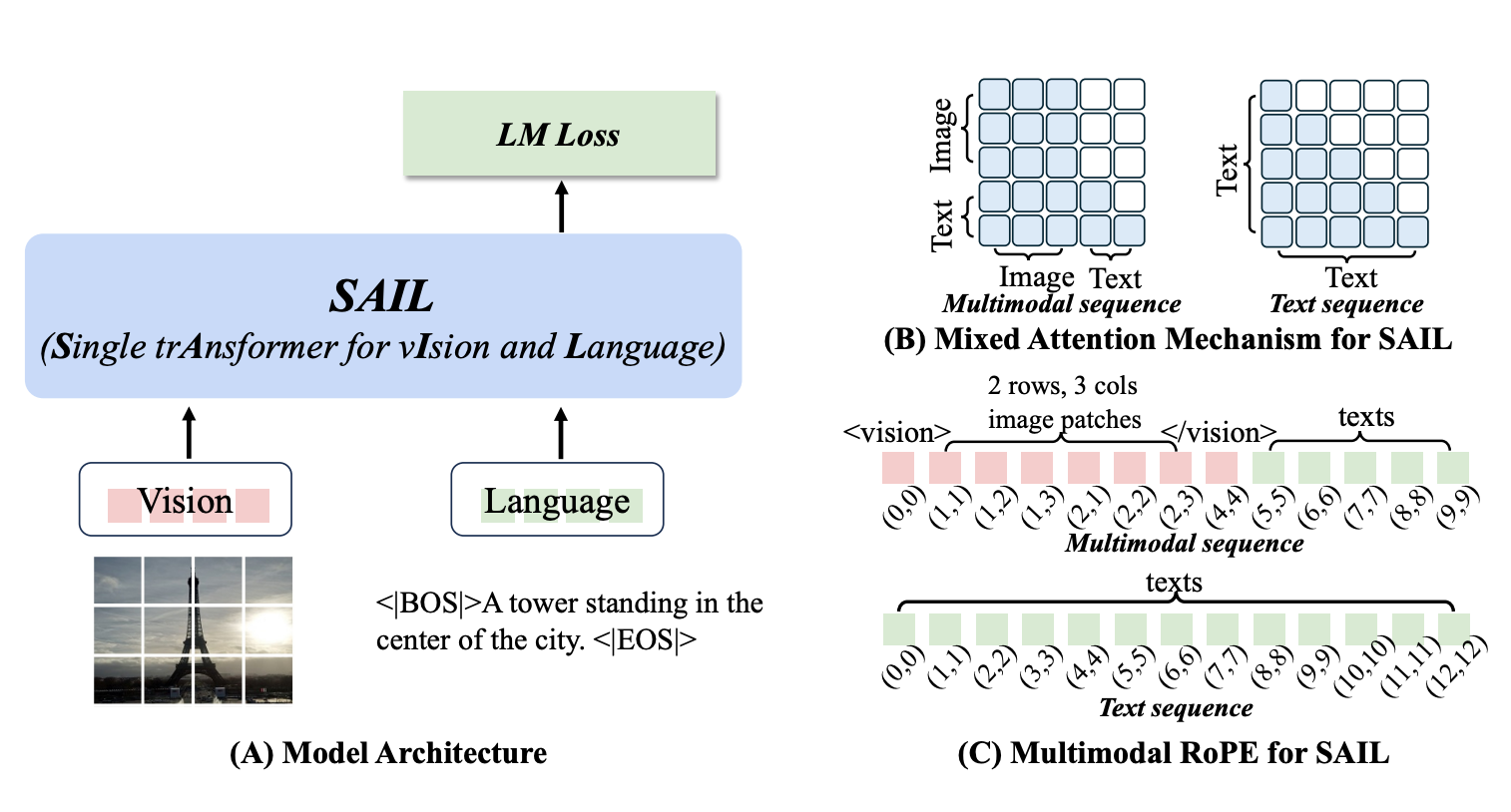
Weixian Lei^*, Jiacong Wang^*, Haochen Wang^*, Xiangtai Li, Jun Hao Liew, Jiashi Feng, Zilong Huang†. ICCV 2025,Highlight code / pdf We systematically compare SAIL’s properties—including scalability, cross-modal information flow patterns, and visual representation capabilities—with those of modular MLLMs. |
|
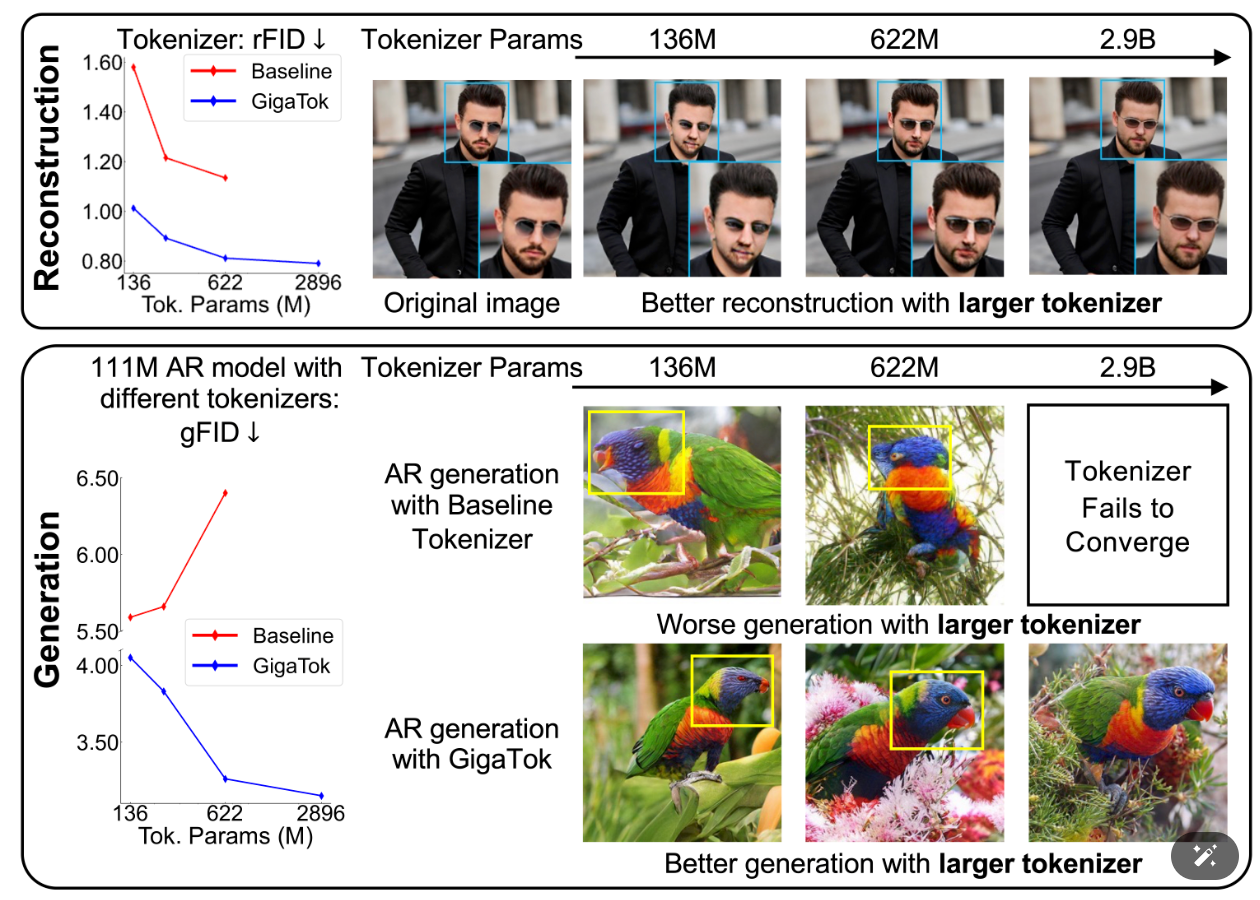
Tianwei Xiong^, Jun Hao Liew, Zilong Huang, Jiashi Feng, Xihui Liu. ICCV 2025 code / pdf We introduce GigaTok, the first method for scaling visual tokenizers to 3 billion parameters. |
|
|
Tao Zhang^, Xiangtai Li, Zilong Huang, Yanwei Li, Weixian Lei, Xueqing Deng, Shihao Chen, Shunping Ji, Jiashi Feng. Arxiv 2025 code / pdf It's the first study to explore the simplest architecture for pixel-wise MLLM tasks, including referring segmentation and visual prompt understanding. |
|
|
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, Bingyi Kang CVPR 2025,Spotlight code / pdf We propose Video Depth Anything for high-quality, consistent depth estimation in super-long videos (over several minutes) without sacrificing efficiency. |
|
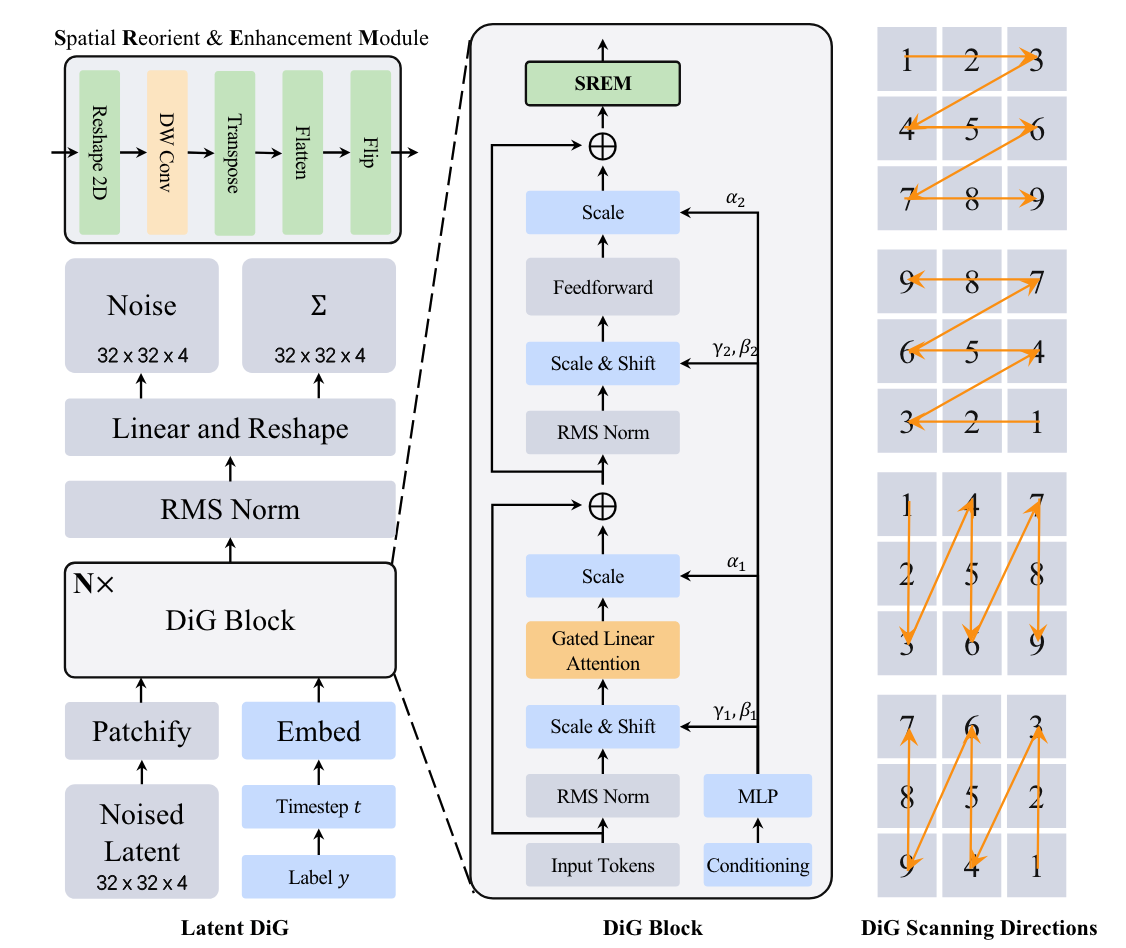
Lianghui Zhu^, Zilong Huang†, Bencheng Liao, Jun Hao Liew, Hanshu Yan, Jiashi Feng, Xinggang Wang† CVPR 2025 code / pdf This work presents Diffusion GLA, the first exploration for diffusion backbone with linear attention transformer. |
|
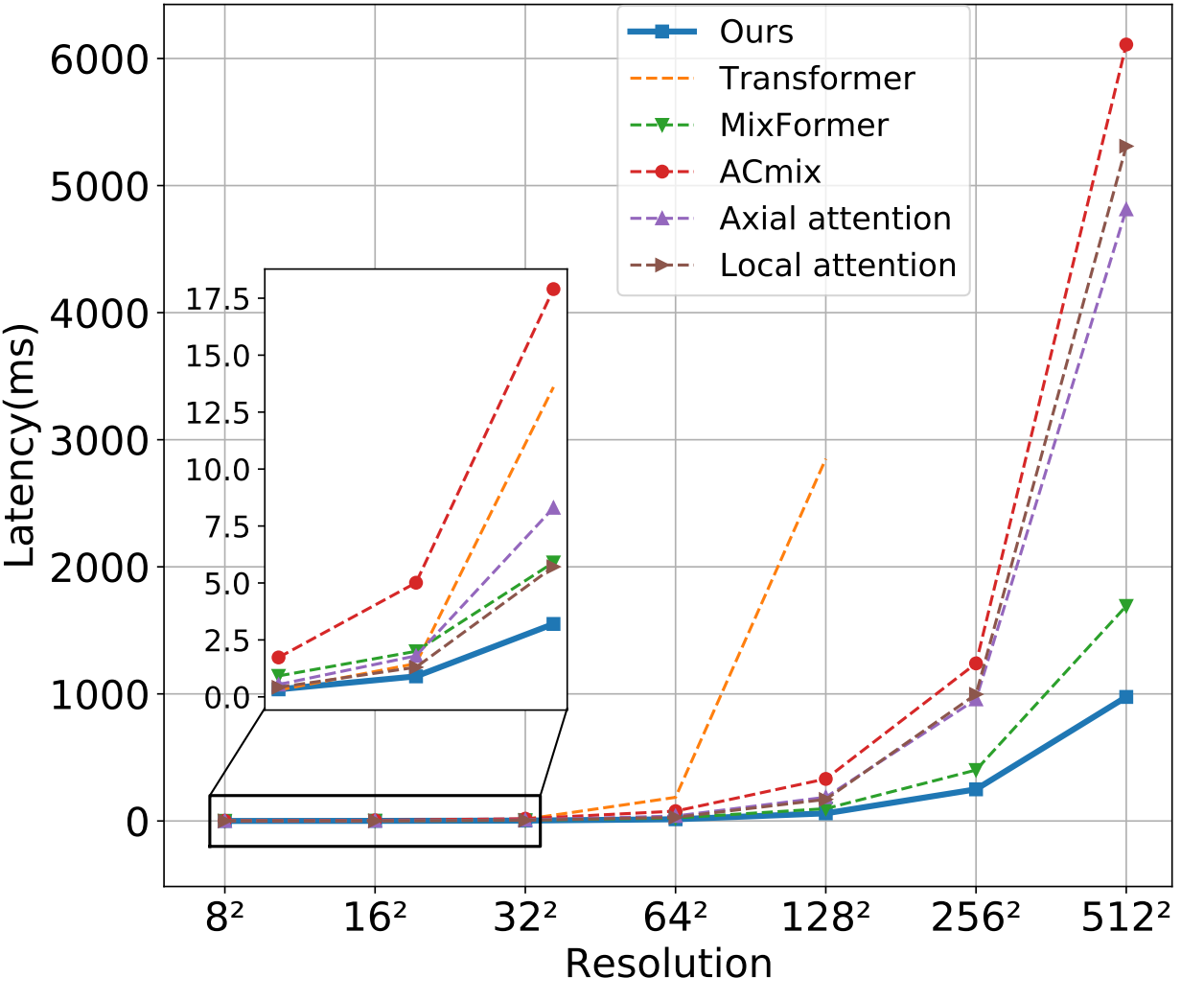
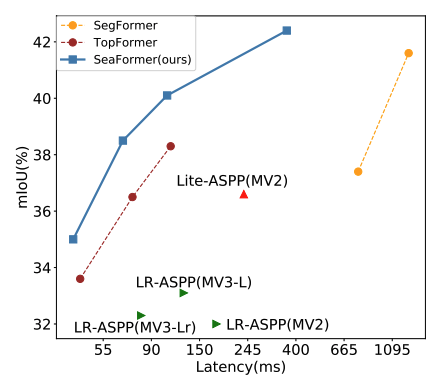
Qiang Wan^, Zilong Huang, Jiachen Lu, Gang Yu, Li Zhang IJCV 2025 code / pdf we introduce a new method squeeze-enhanced Axial Transformer (SeaFormer) for mobile visual recognition. |
|
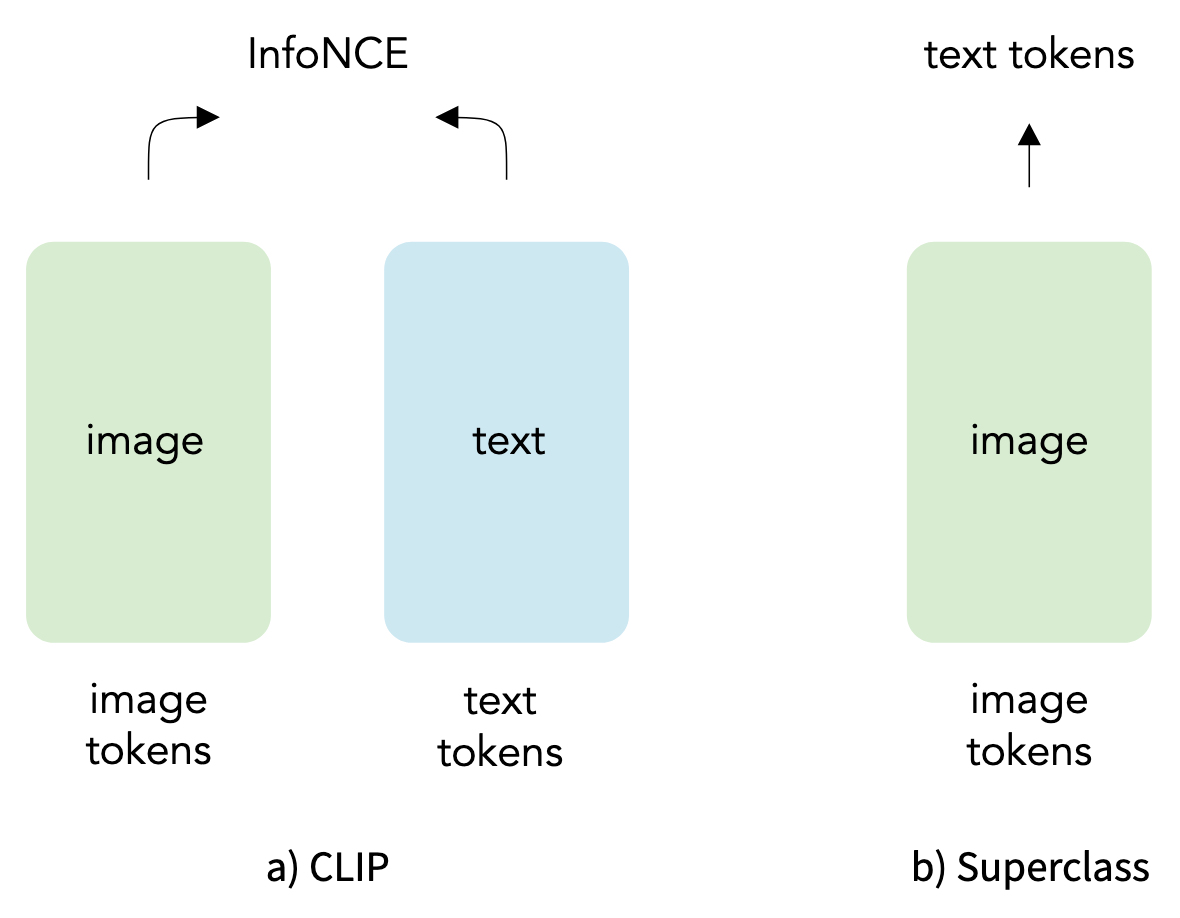
Zilong Huang†, Qinghao Ye, Bingyi Kang, Jiashi Feng, Haoqi Fan NeurIPS 2024 code / pdf We introduce SuperClass, a super simple classification method for vision-language pre-training on image-text data. |

|
Lihe Yang^, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao NeurIPS 2024 code / pdf Depth Anything V2 is trained from 595K synthetic labeled images and 62M+ real unlabeled images. |
|
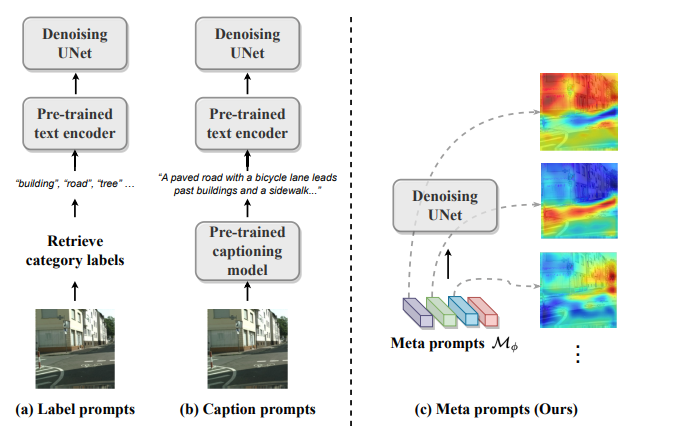
Qiang Wan^, Zilong Huang+, Bingyi Kang, Jiashi Feng, Li Zhang. Arxiv 2024 code / pdf This work presents Meta Prompts, a simple yet effective scheme to harness a diffusion model for visual perception tasks. |

|
Lihe Yang^, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. CVPR 2024 code / pdf This work presents Depth Anything, a highly practical solution for robust monocular depth estimation by training on a combination of 1.5M labeled images and 62M+ unlabeled images. |
|
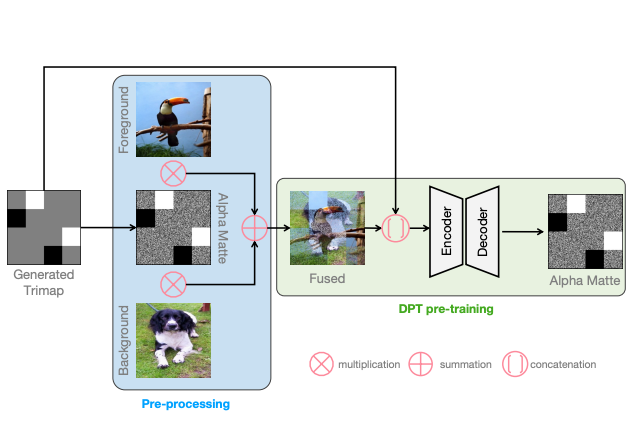
Yanda Li^, Zilong Huang, Gang Yu, Ling Chen, Yunchao Wei, Jianbo Jiao WACV 2024, Oral code / pdf we propose the first self-supervised large-scale pretraining approach for image matting. |
|
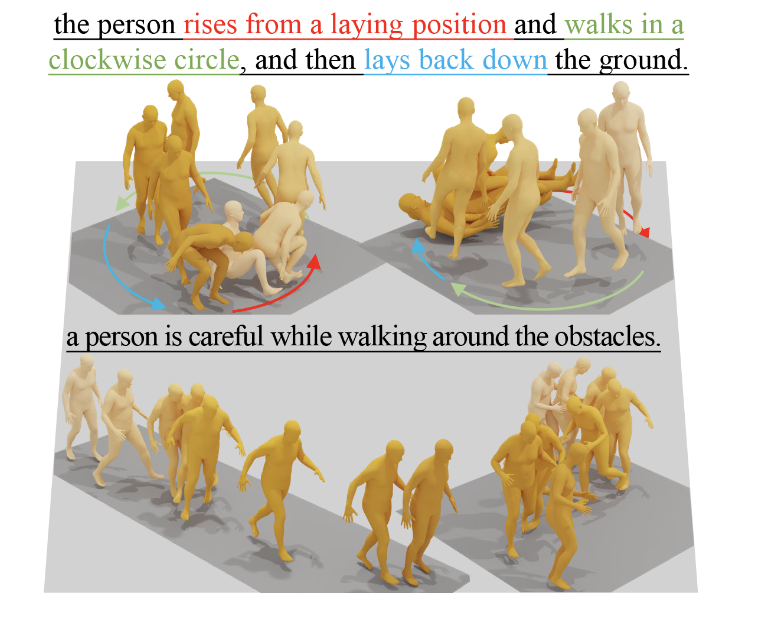
Xin Chen*, Biao Jiang*, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, Jingyi Yu, Gang Yu CVPR 2023 code / pdf we propose a Motion Latent-based Diffusion model (MLD) could produce vivid motion sequences conforming to the given conditional inputs. |
|
Qiang Wan^, Zilong Huang, Jiachen Lu, Gang Yu, Li Zhang ICLR 2023 code / pdf we design a generic attention block characterized by the formulation of squeeze Axial and detail enhancement for mobile vision. |
|
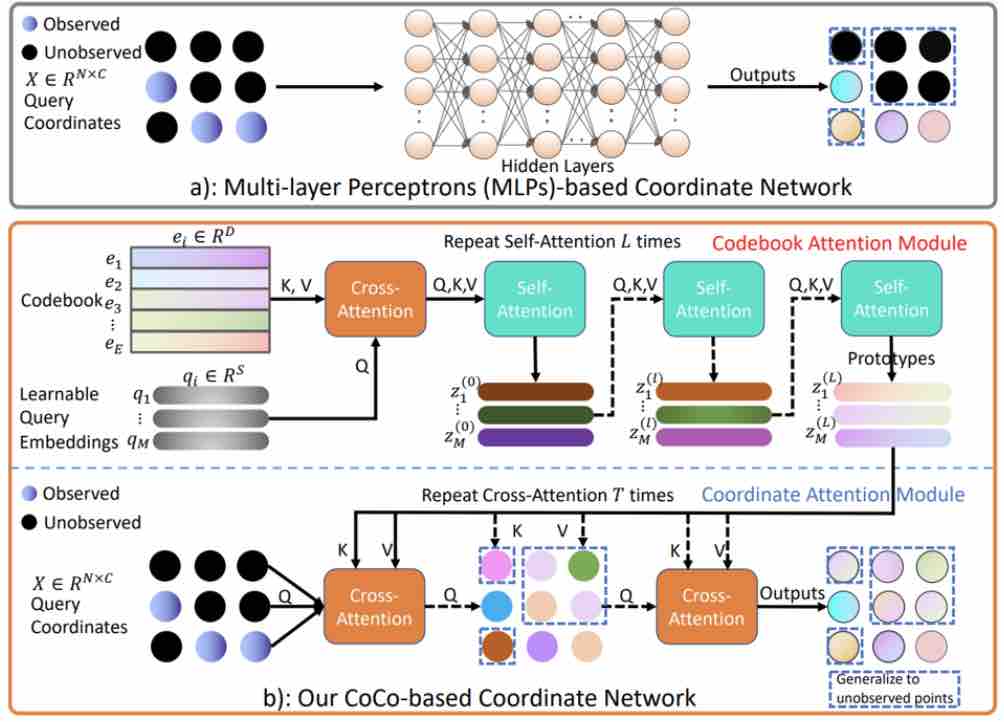
Fukun Yin*, Wen Liu*, Zilong Huang, Pei Cheng, Tao Chen, Gang Yu NeurIPS 2022 code / pdf CoCo-INR is a novel framework for implicit neural 3D representations, which builds a connection between each coordinate and the prior information. |
|
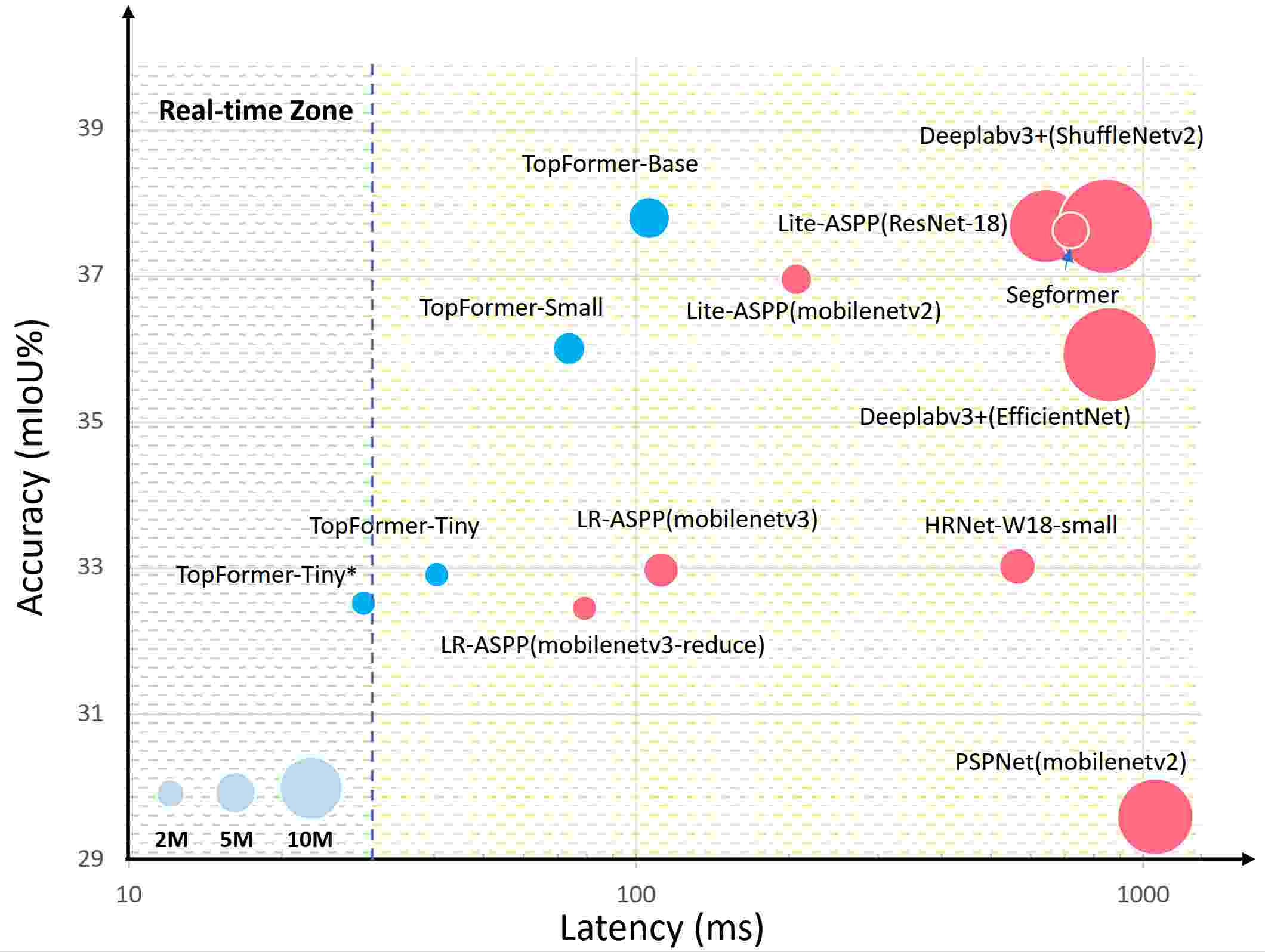
Wenqiang Zhang^*, Zilong Huang*, Guozhong Luo, Tao Chen, Xinggang Wang, Wenyu Liu, Gang Yu, Chunhua Shen CVPR 2022 code / pdf Topformer is the first work that makes transformer real-time on mobile devices for segmentation tasks. |
|
|
Zilong Huang, Youcheng Ben, Guozhong Luo, Pei Cheng, Gang Yu, Bin Fu arXiv 2021 code / pdf we revisit the spatial shuffle as an efficient way to build connections among windows in window-based self-attention. |
|
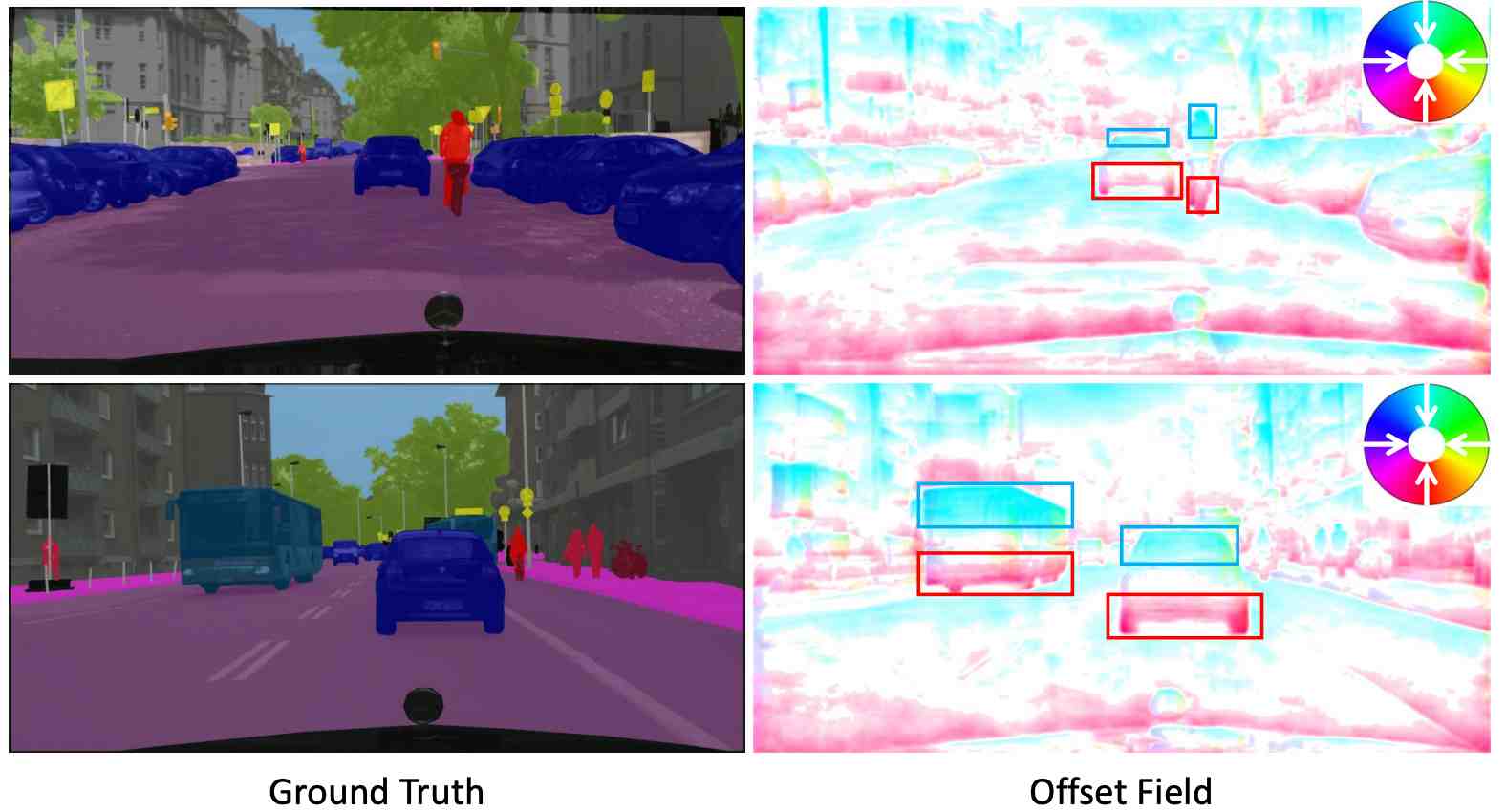
Zilong Huang, Yunchao Wei, Xinggang Wang, Wenyu Liu, Thomas S. Huang, Humphrey Shi TPAMI 2021 code / pdf we focus on the feature misalignment issue in previous popular feature aggregation architectures for semantic segmentation. |
|
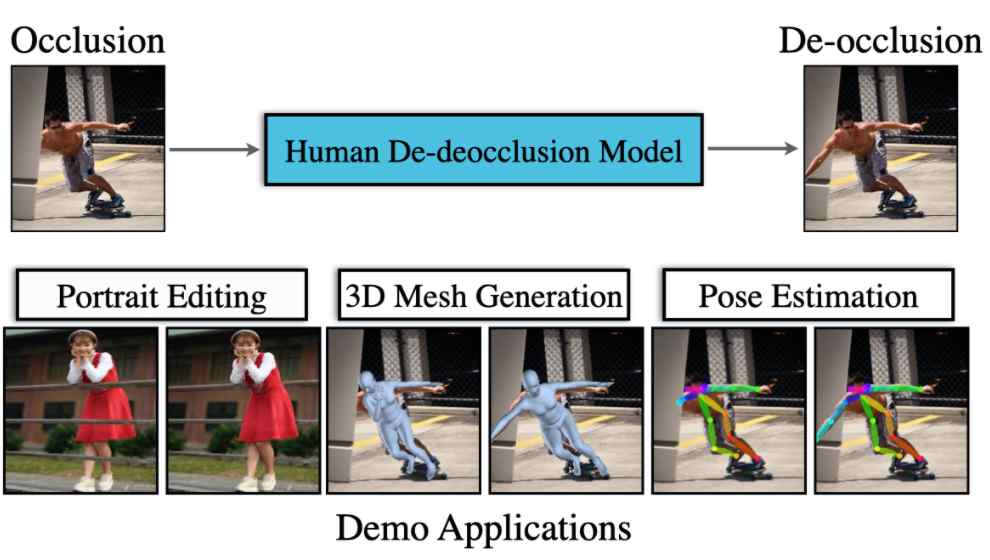
Qiang Zhou, Shiyin Wang, Yitong Wang, Zilong Huang, Xinggang Wang CVPR 2021 dataset / pdf we tackle the problem of human de-occlusion which reasons about occluded segmentation masks and invisible appearance content of humans. |

|
Haichao Yu, Ning Xu, Zilong Huang, Yuqian Zhou, Humphrey Shi. AAAI 2021 we propose HDMatt, a first deep learning based image matting approach for high-resolution inputs. |
|
|
Mang Tik Chiu*, Xingqian Xu*, Yunchao Wei, Zilong Huang, Alexander Schwing, Robert Brunner, Hrant Khachatrian, Hovnatan Karapetyan, Ivan Dozier, Greg Rose, David Wilson, Adrian Tudor, Naira Hovakimyan, Thomas S Huang, Honghui Shi CVPR 2020 dataset / pdf / video we present Agriculture-Vision: a large-scale aerial farmland image dataset for semantic segmentation of agricultural patterns. |
|
|
Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Humphrey Shi, Wenyu Liu, Thomas S. Huang ICCV 2019 |TPAMI 2020 code / pdf More than 3000 citations, PaperDigest Most Influential ICCV 2019 papers (5th). Applications of CCNet also include AlphaFold2. we propose a Criss-Cross Network (CCNet) for obtaining full-image contextual information in a very effective and efficient way. |
|
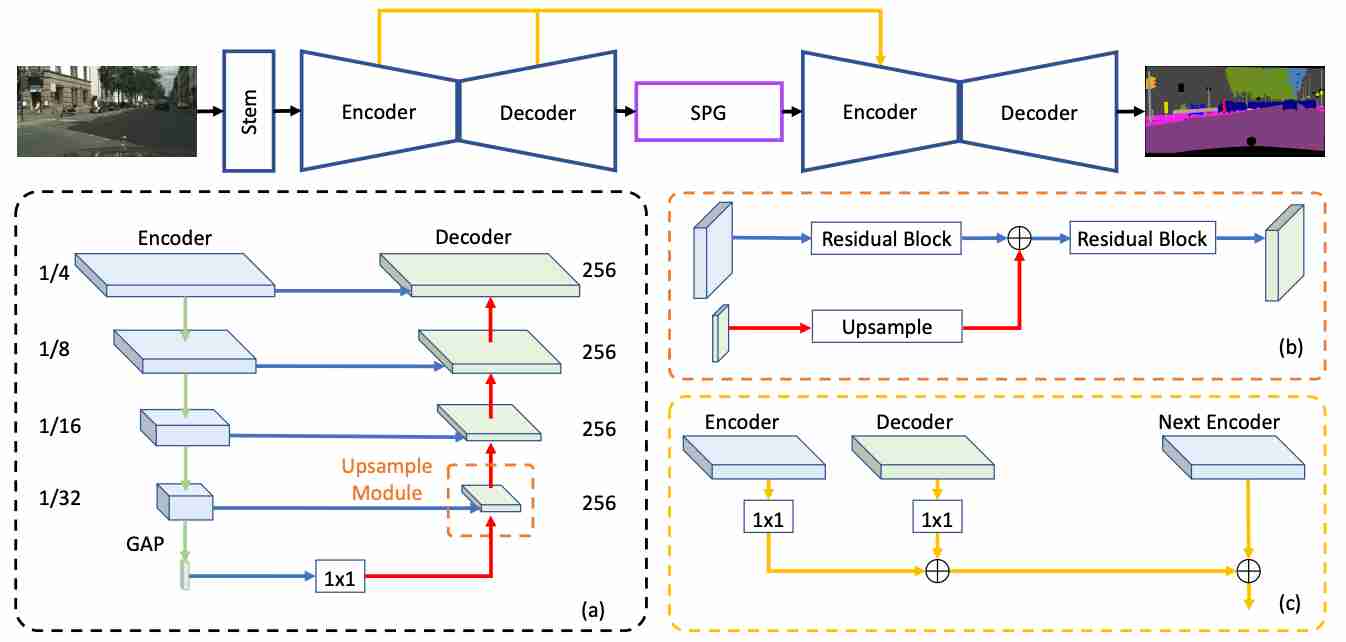
Bowen Cheng, Liang-Chieh Chen, Yunchao Wei, Yukun Zhu, Zilong Huang, Jinjun Xiong, Thomas Huang, Wen-Mei Hwu, Humphrey Shi. ICCV 2019 we propose a Semantic Prediction Guidance (SPG) module which learns to re-weight the local features through the guidance from pixel-wise semantic prediction. |
|
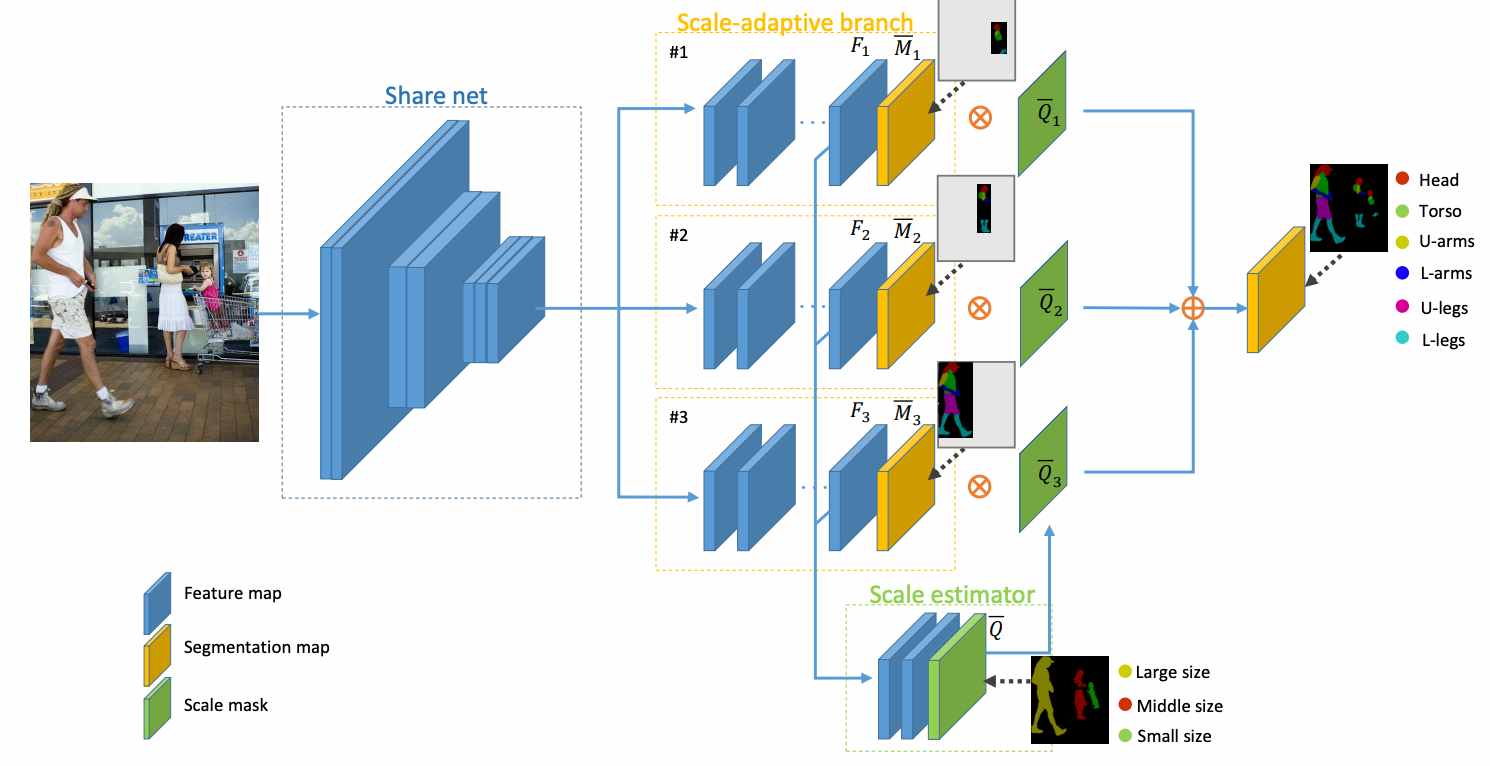
Zilong Huang, Chunyu Wang, Xinggang Wang, Wenyu Liu, Jingdong Wang TIP 2019 code / pdf we propose a Scale-Adaptive Network (SAN) which consists of multiple branches with each one taking charge of the segmentation of the objects of a certain range of scales. |

|
Tao Ruan*, Ting Liu*, Zilong Huang, Yunchao Wei, Shikui Wei, Yao Zhao, Thomas Huang AAAI 2019 code / pdf we identify several useful properties, including feature resolution, global context information and edge details, and perform rigorous analyses to reveal how to leverage them to benefit the human parsing task. |
|
|
Zilong Huang, Xinggang Wang, Jiasi Wang, Wenyu Liu, Jingdong Wang CVPR 2018 code / pdf we propose to train a semantic segmentation network starting from the discriminative regions and progressively increase the pixel-level supervision using by seeded region growing. |
|
Last updated on March 09, 2022. Thanks to Jon Barron for this minimalist website template. |